DataComp Documentation¶



DataComp is an open source Python package for domain independent multimodal longitudinal dataset comparisons. It serves as an investigative toolbox to assess differences between multiple datasets on feature level. DataComp empowers data analysts to identify significantly different and not significantly difference between datasets and thereby is helpful to identify comparable dataset combinations.
Typical application scenarios are:
- Identifying comparable datasets that can be used in machine learning approaches as training and independent test data
- Evaluate if, how and where simulated or synthetic datasets deviate from real world data
- Assess (systematic) differences across multiple datasets (for example multiple sampling sites)
- Conducting multiple statistical comparisons
- Comparative visualizations
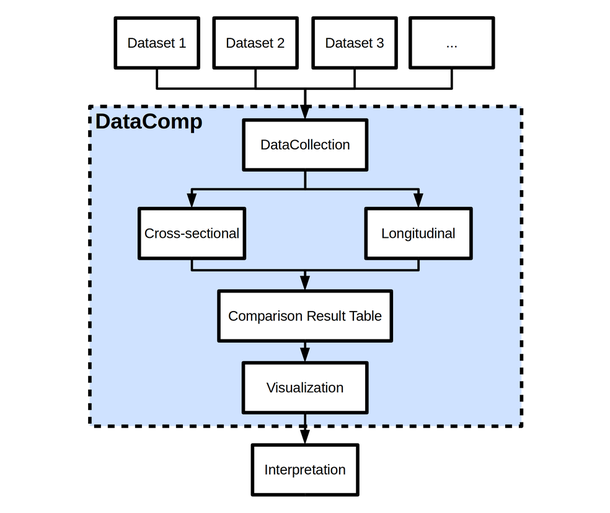
This figure depicts a typical DataComp workflow.
Main Features¶
DataComp supports:
- Evaluating and visualizing the overlap in features across datasets
- Parametric and nonparametric statistical hypothesis testing to compare feature value distributions
- Creating comparative plots of feature value distributions
- Normalizing time series data to baseline and statistically comparing the progression of features over time
- Comparative visualization of feature progression over time
- Hierarchical clustering of the entities in the data sets to evaluate if dataset membership labels are evenly distributed across clusters or assigned to distinct clusters
- Performing a MANOVA to assess the influence of features onto the dataset membership
For examples see Application examples.
Links¶
- Versioning on GitHub
- Documentation on Read the docs
- Distribution via PyPi
Contents:
Code Documentation: